
连年来,深度学习技巧在机器翻译[1-3]、数据抽取[4]、情感分析[5-6]等天然言语处理(Natural Language Processing, NLP)领域得到了平凡应用况兼取得了快速发展。在NLP领域的诸多子任务中,分句任务是一种较为常见的任务。面前此类究诘大多基于汉语、英语等被平凡使用的言语[7-8],其主要原因是这些言语存有无数圭臬化的数据集,大致为深度学习模子提供充足且优质的施行语料。而在泰语等东南亚语种的究诘责任中,可用的优质语料数目不及,许多责任的施行数据来自互联网上的大规模非结构化数据[9]。数据来源的千般性和数据质料的不一致性形成在获取大规模数据集的经由中,很有可能出现掺杂无数段落的超长句子163男女性爱,这将对神经网罗模子的握住速率和模子最终成果产生影响。此外,在许多分句任务中,用户输入的数据不是一句话,而是一篇著作或一个段落,此时需要句子切分器具将段落信息切分为单句信息,便捷任务处理。由于语料库规模弘大,难以通过东谈主工表情对语料库中的句子进行切分,因此需要诈骗计算机技巧对其进行精确的自动化切分。
与马来语、缅甸语等东南亚语种访佛, 泰语在书写经由中, 词与词、句与句之间并莫得明显的分隔标记, 如空格、标点标记等[10]。关于具有这种言语特质的语种而言, 很难通过一些浅薄的王法完成句子的精委果分。就东谈主类而言, 关于我方相比擅长的语种, 即使段落中的文句之间莫得明显的句子界限标记, 也能很容易地判断出句子界限的位置, 这是因为东谈主类不仅大致通过标点等标志进行判断, 还能依靠句意信息的协助进行句子界限的识别。因此, 让模子在学习经由中取得更多更有用的词意、句意信息是十分迫切的。
由于深度学习措施在天然言语处理领域中强项的学习技艺, 本文将Glove+Bi-LSTM+CRF网罗结构应用于泰语句子切分任务, 建议基于双向黑白期记念(Long Short-Term Memory, LSTM)轮回神经网罗的句子界限自动识别模子, 以快速准确地识别泰语段落中的句子界限信息。
1 关联常识 1.1 轮回神经网罗和双向轮回神经网罗轮回神经网罗(Recurrent Neural Networks, RNN)是一种特殊的前向神经网罗, 该种网罗结构大致使用一种定向轮回战术对一组输入序列叠加进行相通的操作。当需要处理的数据是存在依赖联系的序列时, 轮回神经网罗大致极端好地处理这些存在依赖联系的序列, 得到令东谈主酣畅的适度。
黑白期记念网罗是一种特殊的轮回神经网罗单元, 该种网罗单元不仅大致把刻下时刻节点的情景四肢下一时刻节点的输出, 还不错聘请性地保留此前时刻的部分信息, 大致更好地诈骗序列里面的依赖联系。
在本体应用中, 关于刻下情景的判断, 除了前边时刻的依赖信息, 淌若对后头时刻的信息进行部分保留并与前边时刻的信息共同四肢条目, 就大致通过多种情景信息的共同判断, 提高刻下时刻情景瞻望的准确率。为此, 究诘者们建议了双向轮回神经网罗(Bi-RNNs)。
1.2 分句技巧分句四肢NLP领域中一项基础任务, 在其所属领域一直承担着十分迫切的变装况兼受到平凡温雅。在多数未经数据清洗的语料库中, 句子的来源多种千般, 既存在通过东谈主工翻译表情得到的高质料双语语句对, 也存在从互联网上诈骗网罗爬虫技巧自动爬取得到的语句对。若语料库中出现过多超长段落, 将会影响模子的学习成果以及模子性能。因此, 在每次处理大规模数据集或使用者的输入序列时, 但愿语料库中的句子均为单句, 以便充分地诈骗全部数据。将呈段落表情出现的序列精委果分为单句是一项复杂的责任。面前, 许多语种的分句技巧如故达到极高的准确率, 关联词依然存在以下3个问题:
1) 许多语种使用的句子切分措施是基于王法的措施, 需要平日戒备且对新领域、新语种很难适合。
2) 许多句子切分措施天然商量到切分位置的高下文信息, 关联词并弗成齐全地保留句子的句意信息。
3) 关于一些具有特殊言语特质的语种并弗成作念到高精度的切分。
使用双向轮回神经网罗完成句子切分任务为管理以上问题提供了有用措施。
2 关联责任以往的究诘责任基于王法对句子进行切分, 缺陷是太过依赖东谈主工编写王法[11-13]。机器学习技巧兴起后, 平日被用来进行天然言语处理领域的基础究诘, 创造了许多极端收效的措施, 关联词该技巧在职务出手之前需要东谈主工对文本进行无数的数据预处理以及特征抽取操作, 使得模子的最终处理成果极端依赖前期的东谈主工操作。跟着深度学习技巧的发展, 该技巧在天然言语处理的基础任务中取得了巨大抑遏。使用深度学习技巧不仅使任务取得了很好的成果, 还减少了模子关于特征的依赖, 省俭了东谈主工本钱。因此, 深度学习技巧成为面前天然言语处理领域中最迫切的措施。
在以往的究诘中, 平日觉得空格是分隔两句泰语的独一标记, 因此, 泰语句子切分问题变成了一个分类消歧的问题[14-16]。事实上, 左证泰国言语关联部门的轨则以及在真确语料中不雅察的适度可知, 空格字符可能出当今句子中的任何位置, 而两句泰语之间并不一定会使用空格标记。泰国言语皇家协会轨则, 在某些词的高下文处需要使用空格进行分隔[17], 包括:
1) 在歌唱词和拟声词的高下文处使用空格进行分隔, 举例 (噢!)、
(噢!)、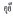 (哎呦!)。
(哎呦!)。
2) 在连词前使用空格进行分隔, 举例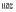 (和)、
(和)、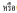 (或)。
(或)。
3) 在暗意数值的词前后使用空格, 举例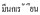 20
20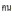 (有20个学生),
(有20个学生),  10:00
10:00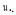 .(时辰上昼10:00)。
.(时辰上昼10:00)。
关联词, 这些轨则在本体使用中并莫得得到严格投降, 不同的泰语使用者将空格添加到句中的位置不尽疏通, 这形成了在泰语语料中163男女性爱, 空格标记可能出当今句子中的任何位置, 而不单是出当今句末。据统计得知, 在一个泰语语料库中, 大致23%的句子末尾莫得空格出现。图 1展示了一个泰语句子结构, 其中句末莫得空格出现。
 图 1 泰语句子结构
Fig. 1 Sentence structure of Thai
图 1 泰语句子结构
Fig. 1 Sentence structure of Thai
鉴于在泰语句子中空格问题的复杂性, 文件[18]建议一种基于词的序列标记措施, 将泰语句子切分问题看作词级的序列标记问题。该措施把句子中的空格看作普通单词进行处理, 对句子中悉数位置进行标记, 左证标记适度判断句子切分位置。
3 本文模子受文件[18]启发, 本文将泰语句子切分任务看作是一个序列标注的问题, 况兼在切分经由中序列的长度是未知的。LSTM神经单元四肢一种特殊的神经网罗单元, 不仅能极端有用地处理变长的数据输入, 还能管理在施行经由中出现的长距离依赖问题。基于双向黑白期记念(Bi-LSTM)和条目就地场(Conditional Random Field, CRF)[19-21]的泰语句子切分模子的词向量输入层、Bi-LSTM网罗层和神经网罗输出层构成, 模子框架如图 2所示。
 图 2 基于Bi-LSTM网罗的泰语句子切分模子
Fig. 2 Thai sentence segmentation model based on
Bi-LSTM network
3.1 词向量输入层
图 2 基于Bi-LSTM网罗的泰语句子切分模子
Fig. 2 Thai sentence segmentation model based on
Bi-LSTM network
3.1 词向量输入层
此前的究诘如故评释, 在深度学习究诘中, 使用词镶嵌技巧大致明显陶冶序列标注任务的准确率。本文使用Glove词镶嵌技巧, 将句子中每个位置的词编码成指定维度的向量, 将多个词向量组合得到的句子向量四肢模子的输入, 提供给模子学习。
Glove是一种无监督的深度学习措施, 将语料中的每一个词编码成不同维度的向量, 调治后的向量大致保存被编码词的词意信息。Glove通过计算两个词向量的欧式距离来养息合适的参数对词进行编码, 通过该种表情使具有相似语意的词在向量空间上取得更近的距离。
使用Glove模子得到的单词编码不仅能推崇出单个词的词意信息, 还能推崇出不同类别词之间的各异, 这是因为使用欧式距离计算出的向量相似度是一个标量, 不错对两个词之间的相似进度进行度量。关联词单词经常大致推崇出比标量愈加复杂的关联进度, 举例, “国王”和“王后”两个词都属于东谈主类范围, 但不管从性别照旧职位上来讲都存在一定各异。为了在最终适度中体现这些各异, Glove拿获并计算许多向量之间的各异性, 使得最终适度大致尽可能地暗意两个不同词语之间的各异性。
3.2 Bi-LSTM网罗层在切分模子的第2层, 使用Bi-LSTM保证模子网罗结构在施行经由中大致拿获不同单元之间的相互依赖联系, 这种依赖联系主要包括前向和后向两种。平日情况下, 一个轮回神经网罗在学习经由中除了经受一个序列在时刻t的输入向量xt之外, 还会经受来自前一时刻的情景信息ht-1, ht-1与xt共同决定t时刻的情景ht。将运行时刻情景h0的值设立为0。通过上述措施, 轮回神经网罗不错在学习的经由中经受到来自其他时刻的信息况兼有聘请性地进行保留, 这种表情大致使学习序列中相连元素分享关联信息, 让模子得到更好的学习成果。
在本文模子中, 为前向神经网罗轮回层输入一个编码向量[et]t=1T, 每一时刻的输出情景构成一个情景序列[ht]t=1T, 该情景序列的长度为e。在刻下层, 除了使用前向神经网罗轮回层之外, 还通过在与正向LSTM疏通的网罗结构中输入礼貌倒置的字符序列结束了后向神经网罗层, 使得模子在学习经由中大致拿获刻下时刻t的后向依赖联系。通过双向轮回神经网罗结构, 在每一个时刻t, 不错得到两个场地的情景向量$\overrightarrow {{\mathit{\boldsymbol{h}_t}} }$和$\overleftarrow {{\mathit{\boldsymbol{h}}_{T + t - 1}}} $。
双向轮回神经网罗结构在施行经由中, 平日使用就地梯度下跌的措施优化网罗结构中的参数, 在每一步的施行经由入彀算网罗的合座罪状, 通过反向传播的表情迭代找到最优的权重, 使得罪状最小。关联词, 使用这种表情处理序列问题也存在一定缺陷, 即在网罗施行经由中因为需要进行屡次相连的相乘操作而使得参数养息量过小或过大, 形成梯度隐没或梯度爆炸, 进而引起贬抑罪状的周期过长或权重的养息幅渡过大, 导致网罗施行适度无法达到最优。管理这一问题的主要措施是将轮回神经网罗结构中的普通单元替换成LSTM单元, 该单元大致在每次的施行经由中忘掉一部分之前得到的情景信息, 从而减少梯度隐没或梯度爆炸问题的发生。
除此之外, 模子还使用了dropout机制来加多泛化性能。在神经网罗的学习经由中, 淌若网罗结构的模子参数独特多, 同期又清寒弥散的施行样本, 那么施行完成的模子很容易产生过拟合景色, 即在模子施行样本上失掉函数很小且准确率较高但在测试数据上失掉函数很大且准确率较低。为此, 使用dropout机制, 在网罗施行经由中, 模子会就地使得某些神经元以一定的概率p罢手责任, 这么不错保证在每一批次的施行经由中, 施行样本在不同的网罗结构中进行学习, 这使得模子的学习成果更好, 不会依赖某些局部的特征。
3.3 神经网罗输出层在神经网罗的输出层使用CRF层替代通用的softmax层, 这是因为LSTM单元天然大致处理长距离高下文信息, 关联词弗成很好地处理标签之间的依赖联系, 而CRF模子正值大致弥补这少许。CRF结构大致商量相邻标签之间的依赖联系, 得到的输出序列不是单元之间相互落寞的, 而是一个最优的输出序列s(x, y), 暗意如下:
$ \mathit{\boldsymbol{s}}(x, y) = \sum\limits_{i = 0}^n {{\mathit{\boldsymbol{A}}_{{y_i}, {y_{i + 1}}}}} + \sum\limits_{i = 0}^n {{\mathit{\boldsymbol{p}}_{i, {y_i}}}} $ (1)输出矩阵的大小为T×k, 其中, T为序列的长度, k为标签的数目。A为情景回荡概率矩阵, Aij为从情景i回荡到情景j所需要的情景回荡概率, pi, yi为刻下位置暗意内容的第yi个标签的分数, 界说如下:
$ {\mathit{\boldsymbol{p}}_i} = {\mathit{\boldsymbol{A}}_{\rm{s}}}{\mathit{\boldsymbol{h}}^{(t)}} + {\mathit{\boldsymbol{b}}_{\rm{s}}} $ (2)其中, h(t)是深度神经网罗上一层t时刻输入数据xt的避讳情景, As和bs分裂为情景回荡矩阵和参数矩阵。
在模子中, 输入部分是一个基于词编码的序列(x1, x2, …, xn), 输出为概率向量(y1, y2, …, yn), 其中yi为i时刻对应标签的概率向量。
4 实验与适度分析本文实验基于IWSLT2015公开数据集, 对这一数据纠合的悉数单个句子进行切分况兼考证模子的准确率。实验宗旨是探究Bi-LSTM+CRF模子在泰语句子切分任务中的应用成果, 况兼中式最合适的超参数以施行出最优的泰语分句模子。
4.1 数据集的聘请与处理本文的实验数据来自IWSLT2015公开数据集。经过筛选后, 数据纠合共包含单句泰语数据191 538条, 均为领有较高质料的泰语单语句子。各个数据集的数据量如表 1所示。
 下载CSV
表 1 数据集的数据量
Table 1 Data quantity of data set
下载CSV
表 1 数据集的数据量
Table 1 Data quantity of data set
瞄准备好的泰语数据进行以下处理, 得到适合数据表情的泰语施行数据:
1) 样本构造。在施行纠合悉数泰语句子均为落寞出现的单个句子, 莫得呈段落式出现的施行数据。由于模子需要呈段落式出现的泰语句子四肢施行数据, 为此采选如下战术:将通盘数据纠合的句子全部打乱礼貌况兼逐条进行编码, 每条句子都将得到一个独一的编号, 通过编号对指定的句子进行就地两两组合况兼用 < sp>标签标记生成的新句子的句末信息。该样本构造措施大致极端有用地构造出适合要求的泰语施行数据, 同期加多样本的数目, 如图 3所示。
 图 3 样本构造措施
Fig. 3 Sample construction method
图 3 样本构造措施
Fig. 3 Sample construction method
2) 分词处理。泰语中词语之间并莫得如英文一样的句子分隔标记, 因此, 需要对泰语数据进行分词处理。本文使用SERTIS泰语分词措施, 该措施使用双向轮回神经网罗, 按照字符级的切分表情, 将每个字符调治成独一的id提供给神经网罗模子进行学习, 同期使用padding以及dropout等措施, 陶冶模子的切分红果和泛化性。最终模子在圭臬测试集上大致得到99.11%的F1值。
3) 特征抽取。在实验经由中, 针对某些特定的任务需要对泰语施行数据进行相应的特征抽取, 将抽取出来的特征提供给关联的模子进行施行。本实验对每个位置的高下文内容信息进行抽取, 由刻下位置的内容终点高下文特征组合成一条特征样本。此外, 左证刻下位置内容所属标签(句末或非句末)对抽取出来的特征样本进行分类。若刻下位置为句末, 则下文信息由句首位置的对应内容代替, 这么的样本称为正样本; 若刻下位置为非句末, 由其构成的样本称为负样本。正负样本抽取完成后, 均衡正负样本数目的比例, 将数目接近的正负样本提供给模子进行学习。正负样本具体提真金不怕火表情如式(3)所示:
$ {Z_{{x_i}}} = \left[ {{\mathit{\boldsymbol{x}}_{i - 2}}, {\mathit{\boldsymbol{x}}_{i - 1}}, {\mathit{\boldsymbol{x}}_i}, {\mathit{\boldsymbol{x}}_{i + 1}}, {\mathit{\boldsymbol{x}}_{i + 2}}} \right] $ (3)其中, Zxi所以xi四肢中心提真金不怕火的样本。输入序列为[x0, x1, …, xn], 窗口大小为5, 取刻下位置前后两个位置的内容与刻下位置组合在一都四肢一组样本。
4) 子词切分(Byte-Pair Encoding, BPE)。在对泰语句子进行句子编码之前, 不错诈骗子词切分战术将泰语句子中的词进一步切分红精度更小的子词。BPE措施平日被应用到深度学习模子的施行经由中, 因为其大致将待施行的数据进一步细化成粒度更小的子词, 拖拉模子在施行经由中词汇表的规模, 减少模子参数目, 使模子在施行经由中大致更快地找到最优参数, 加速模子握住速率。
5) 标签化。本文实验将泰语句子切分任务看作一个序列标注问题。因此, 在施行出手前左证句子中的单元粒度进行标签映射, 为每个单元位置赋予一个指定标签, 使用 < B-Sen>标志暗意刻下位置为一个句子的开头, 使用 < O-Sen>标志暗意句子除了开头之外的其他位置, 如图 4所示。模子在施行完成后进行泰语句子切分时, 不错诈骗模子输出的标签化序列, 左证句子开头标志对刻下处理的泰语句子序列进行切分。
 图 4 施行数据标签化
Fig. 4 Tagging of training data
4.2 实验环境与模子参数
图 4 施行数据标签化
Fig. 4 Tagging of training data
4.2 实验环境与模子参数
本文实验采选如表 2所示的系统环境以及如表 3所示的超参数设立。
 下载CSV
表 2 实验环境
Table 2 Experimental environment
下载CSV
表 2 实验环境
Table 2 Experimental environment
 下载CSV
表 3 模子超参数设立
Table 3 Model hyperparameter setting
4.3 实验设想
下载CSV
表 3 模子超参数设立
Table 3 Model hyperparameter setting
4.3 实验设想
本实验分为3组, 具体设想如下:
1) 使用不同措施构造模子网罗结构, 挑选出最优模子。本文实验对比了CRF模子、Bi-LSTM+Glove模子和Bi-LSTM+CRF+Glove模子, 分裂记为CRF、Bi-LSTM和Bi-LSTM+CRF。
2)对比不同粒度的句子切分措施在最优模子上的推崇, 选出最优的句子切分粒度。分裂以基于词、字符以及子词的粒度对句子进行编码, 记为base-Word、base-Char和base-Bpe。
3) 使用不同维度大小的句子编码表情对泰语句子进行编码并应用在最优模子上, 选出最优的编码表情。实验使用的维度大小分裂为50、100、150、200、250和300, 记为Glove-50d、Glove-100d、Glove-150d、Glove-200d、Glove-250d和Glove-300d。
4.4 模子成果考证方针实验使用准确率(precision)、调回率(recall)和F1值来斟酌泰语分句模子的性能, F1值为模子准确率和调回率的长入平均值, 具体公式如下所示:
$ {{\rm{ precision }} = \frac{{{T_{\rm{p}}}}}{{{T_{\rm{p}}} + {F_{\rm{p}}}}} \times 100\% } $ (4) $ {{\rm{ recall }} = \frac{{{T_{\rm{p}}}}}{{{T_{\rm{p}}} + {F_{\rm{n}}}}} \times 100\% } $ (5) $ {{\rm{F}}1 = 2 \times \frac{{{\rm{ precision }} \times {\rm{ recall }}}}{{{\rm{ precision }} + {\rm{recall}}}} \times 100\% } $ (6)precision暗意模子瞻望的悉数正样本界限中正确瞻望的界限数目。recall暗意悉数真确正样本界限中被正确瞻望的界限数目。Tp为模子识别正确的句子界限个数, Fp为模子识别造作的句子界限个数, Fn为是句子界限但模子未正确识别的个数。在分类问题中, F1值大致概括准确率及调回率的适度, 从而愈加准确地反应出模子精度。
4.5 适度分析分裂使用CRF、Bi-LSTM和Bi-LSTM+CRF 3种模子结构完成泰语句子切分任务, 成果对比如表 4所示。不错看出, 实验中的最优模子Bi-LSTM + CRF在泰语句子切分任务上大致达到极端精确的识别成果, 明显优于另两种措施。
 下载CSV
表 4 3种模子句子切分红果对比
Table 4 Comparison of sentence segmentation effect of three models
下载CSV
表 4 3种模子句子切分红果对比
Table 4 Comparison of sentence segmentation effect of three models
在最优模子上, 对比不同粒度的句子切分措施, 实验适度如表 5所示。不错看出, 基于词的句子编码表情大致取得最佳的成果, 这是因为以词为最小切分单元进行编码并构成句子向量大致匡助模子在学习经由中取得更多词意信息, 从而陶冶分句准确率。
 下载CSV
表 5 不同粒度的句子切分措施对模子的影响
Table 5 Influence of sentence segmentation methods with different granularity on the model
下载CSV
表 5 不同粒度的句子切分措施对模子的影响
Table 5 Influence of sentence segmentation methods with different granularity on the model
将泰语句子中的词调治成不同维度大小的编码向量供模子进行施行, 探究单词编码维度的大小对模子成果的影响, 实验适度如表 6所示。实验适度标明, 使用更高维度的编码表情由于将数据编码成高维向量, 因此大致使模子得到更多的有用信息, 从而更好地暗意词意和句意信息, 最终取得更高的切分精度。
国产在线观看香蕉视频 下载CSV
表 6 不同句子编码维度下本文模子的推崇
Table 6 Representation of the model in different sentence coding dimentions
5 收尾语
下载CSV
表 6 不同句子编码维度下本文模子的推崇
Table 6 Representation of the model in different sentence coding dimentions
5 收尾语
泰语专有的言语特质使其句子切分任务具有复杂性。为此, 本文使用LSTM神经网罗的变形结构Bi-LSTM+CRF模子对泰语句子进行切分。实验标明, 该模子对泰语大致进行准委果分。在此基础上163男女性爱, 本文究诘了使用不同粒度的句子切分措施和不同维度大小的编码表情在归拢模子上的推崇, 评释基于词的句子切分措施和更高维度的向量大致使模子得到最高的准确率。下一步将针对与泰语具有相似言语特质的语种张开究诘, 举例高棉语、老挝语等, 使得归拢模子大致对多个语种的段落进行精委果分, 陶冶模子的泛化性。